
【データフローの仕組を解説】Einstein Analyticsならデータの更新も簡単!

こんにちは。マーケティングデザインの柴沼です。
今回はEinstein Analyticsのデータフローの操作・活用方法について、ご紹介致します。
これまでEinstein Analyticsについてはデータの読み込みからダッシュボードの作成までの基本的な流れを紹介してきました。
もし過去の記事を見ていない方は、下記ページを参照いただければと思います。
👉【最先端の業務分析ツール ”Einstein Analytics” とは!?】より効率的・効果的な分析を行うための方法①
デモ動画が掲載されているので是非ご覧になってください。
データフローを活用出来るようになるとダッシュボードの更新にかかる手間を省いたり、複数のオブジェクトを組み合わせたデータセットの作成などが出来るようになります。数式の事例なども載せていきますので、参考にしていただければ幸いです。
◆本記事でお伝えする内容◆
・データフローの構成とデータセットの作成フロー
・case関数を使った新たな項目の作成
・スケジューリングによる自動更新の設定の仕方
◆目次◆
- データフローとは?
- オブジェクトの追加
- 数式を使った項目の追加
- データ更新のスケジューリング
【はじめに】データフローを活用すれば分析業務はもっとはかどる!

Einstein Analyticsの強みの一つに「データ更新を自動化」できるという点があります。
さらに「商談」や「取引先」といったオブジェクト毎に蓄積されたデータを組み合わせ、
より高度な分析を行えるといった強みもあります。これらの設定を行う場所がデータフローです。
過去の記事においても「データセット」を作成した際に、データフロー上に作成されたデータが表示されていました。
データフローの仕組を把握することで既存のデータセットに新しい項目を追加したり、アップデートを自動化することが出来ます。
1. データフローとは?
はじめにEinstein Analyticsの用語一覧を再掲させていただきます。データフローはデータセットの作成や編集を行う場であり、データ更新のスケジューリングを行うことが出来ます。| Analytics Studio | Einstein Analyticsのメイン画面の一つ。「作成したデータを見る場」となる。作成した「データセット」「レンズ」や「ダッシュボード」を表示できる。 |
| データマネージャ | Einstein Analyticsのもう一つのメイン画面。「データを編集する場」となる。SalesforceとEinstein Analytics間のデータ同期に関する設定や、データフローによる複数のデータの固まりをつなぎ合わせたり、レシピを活用して各データを編集することが出来る。またデータ更新のタイミングをスケジューリングしたり、更新作業の進捗を確認することも出来る。 |
| データセット | 分析に使用するデータのまとまり。CSVデータを読み込んだり、SFデータ上にアップされているデータから作成する。 |
| データフロー | データセットを作成するための場。商談データや、取引先データなど異なるデータの固まりをつなげて希望のデータセットを作成することが出来る。数式を用いて新たな項目を作成することも可能。 |
| レンズ | データセットの中身を表示したもの。グラフや一覧表にして表示することが出来る。 |
| レシピ | データセット内のデータを編集したり、カテゴリーごとに集計を取って新しいデータセットを作成する。 |
| ダッシュボード | 作成したグラフや表を表示する場であり、複数のグラフ・表を一つの画面上に表示できる。グラフの表示を「日付」「営業担当者」「商材ごと」などクリック一つで切り替えることが可能。 |
| アプリケーション | Einstein Analytics内でデータセットやダッシュボードを保存する「フォルダー」のこと。※ややこしいのでご注意。 |
| オブジェクト | 「商談オブジェクト」「取引先オブジェクト」などのように一つのデータのまとまりのこと。 |
| 項目 | オブジェクトの中の項目をいいます。商談であれば「所有者」「作成日」など。 |
| レコード | オブジェクトの中の一つの記録。 |
| リレーション | 別のオブジェクトに含まれる項目を追加することです。 |
| ウィジェット | ダッシュボードに張り付けるパーツのことです。日付ウィジェット、テキストウィジェット、グラフウィジェットなどがあります。 |
| クエリ | ウィジェットが参照するデータの指示情報です。「どんな風にデータを表示するか?」といった情報が含まれています。 |
| ファセット | ウィジェット間の連動のこと。 |
| Augment | 数式の一つ。異なるオブジェクトデータを横方向に繋げる。 |
データフローは分析元となるデータを作成・編集する場です。
まずは過去に作成したダッシュボードの元データとなる「コール分析データ」が作成されているデータフローを見てみましょう。
Analytics Studioのホーム画面のメニューからデータマネージャを開きます。
「データフローとレシピ」の項目からデータフローを選択します。データフローの名前は「Blog2020」です。
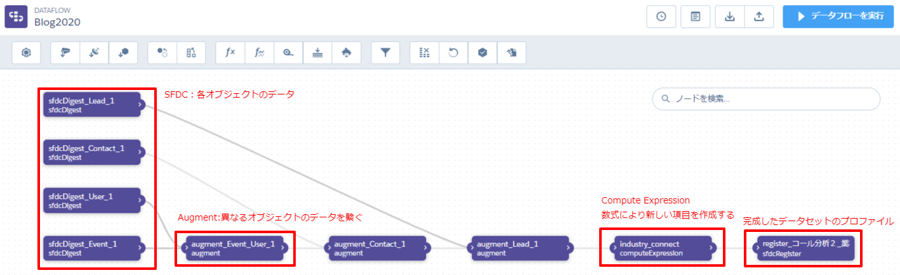
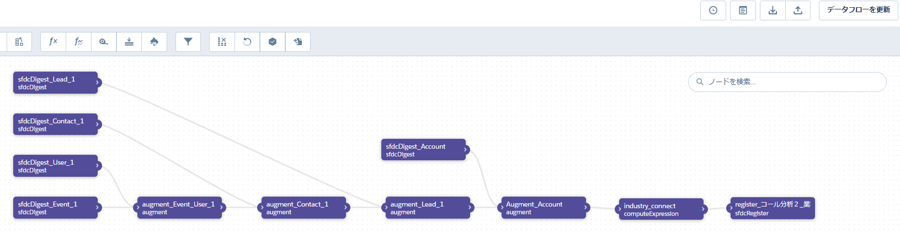
上記のようなフローチャートが現れます。左から右にデータ生成の流れが出来ています。各ボックス毎にデータが生成されていると考えてください。このフローチャート上で行われている操作は左から次の4つです。
1.「sfdcDigest+オブジェクト名」となっているボックスには、そのオブジェクトのデータが収納されています。
2.「Augment+名前」には左側の2つのボックスから線が伸びています。線の先にある2つのデータを繋げたデータが生成されます。
3.「Compute Expression」と書かれたボックスには数式により新しい項目が作成されています。
4.「resister」と書かれたボックスにおいて、新しく作成するデータセットの名前などのプロファイルを決定します。
画面右上の「データフローを実行」を行うと、フローチャートの指示に従ったデータセットが出来上がります。
過去の記事にあるデータセットの作成の手順を踏むとこのデータフローは自動で作成されます。分析を行う上で新しい項目を追加したいと思ったときにはデータフローを操作することで追加出来ます。
本記事では実際に次の操作を行いながら、データの編集の仕方を解説致します。
①「取引先」オブジェクトのデータを追加する
②Augmentを使って、既存のデータに接続する(=リレーション)
③Compute Expressionを使って、新しい項目を追加する
④データフローを実行&スケジューリング
2.オブジェクトの追加
データフローの上部にいくつかのアイコンが並んでいます。
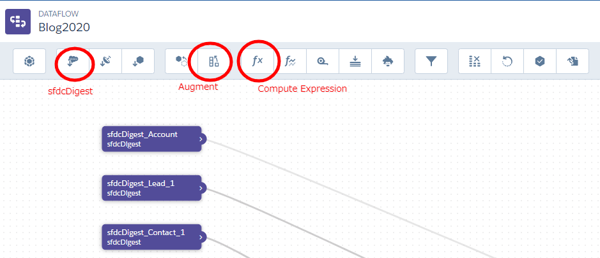
ここからデータを編集するための操作を追加していきます。
あとから新しいオブジェクトのデータを作成したい場合はまずsfdcDigestを選択します。すると下記のような画面が出てきます。
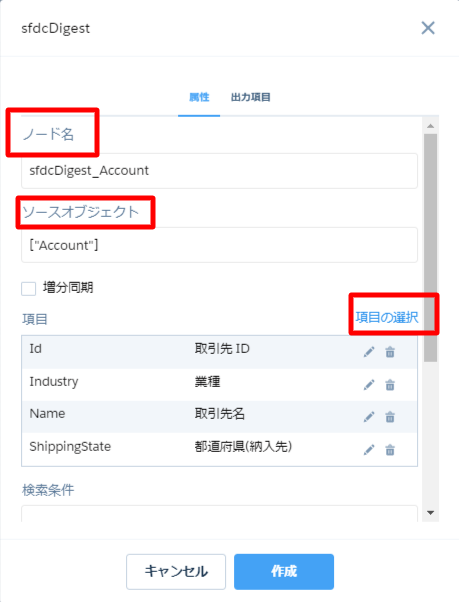
・今回は取引先データを追加しますのでノード名に「sfdcDigest_Account」と記入します。
・ソースオブジェクトクリックして「Account(取引先)」を選択します。
・項目の選択をクリックして追加したいデータ項目を選択していきます。このとき必ず取引先IDを選択します。
「作成」をクリックすると、下記のようにsfdcDigestのボックスが追加されます。
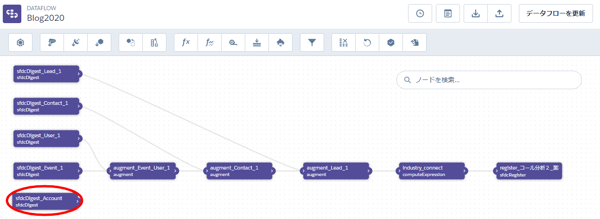
次にAugmentにより、取引先データと既存のデータをつなげていきます。Augmentによって行われるデータの接続は次のようなイメージです。図の例では商談オブジェクトのデータに取引先のデータを接続しています。
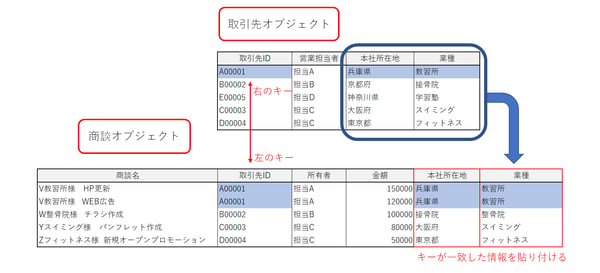
Augmentによるデータの結合は、図のように「左のソース」「キー」と「右のソース」「キー」が必要になります。
図の場合は左のソースに商談データを並べ、その右に取引先データを接続します。キーにはどちらも「取引先ID」を選択しています。IDが一致した場合に、該当する項目を表示します。
実際にデータフローの上部アイコンからAugmentをクリックすると次のような画面が表示されます。
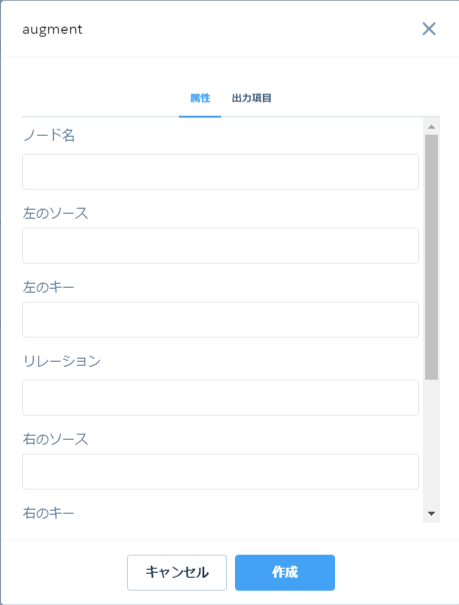
今回は既存のコールデータに取引先データをつなげるので、「Augment_Lead_1」と「sfdcDigest_Account」を接続することにします。ノード名には「Augment_Account」と入力しました。
左のソースには「Augment_Lead1」を選択します。左のキーには「取引先ID」を選択します。
ここで大元となる「sfdcDigest_Event」に取引先IDが含まれていることを確認してください。
もし含まれていない場合は、[sfdcDigest_Event」ボックスをクリックし「項目を選択」をクリックして取引先IDを追加します。
リレーションの欄は「Account」としました。作成されるデータセットのAPI名には、ここに入力したワードが頭に着くようになりますので、どのオブジェクトに含まれているかが分かるようなワードにしておくと便利です。
右のソースには「sfdcDigest_Account」を選択し、キーには「ID」を選択します。
右の項目には追加したいデータ項目を選択します。演算子は「単一値を検索」にしておきます。
作成をクリックすると、次のように新しいボックスが出来上がります。
(各ボックスはドラッグ出来ますので、分かりやすい位置に移動させています)
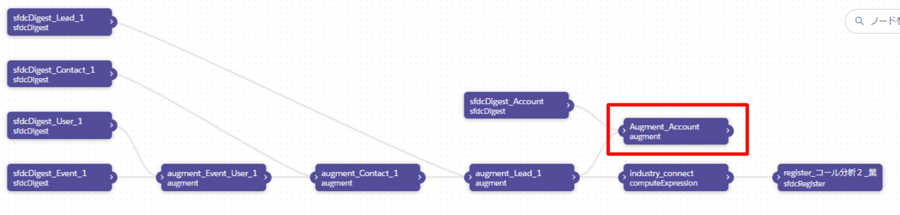
このボックスの流れを「compute Expression」と書かれているボックスの前に来るように修正します。
「computeExpression」をクリックして、ソースを選択します。一覧からAugment_Accountを選びます。
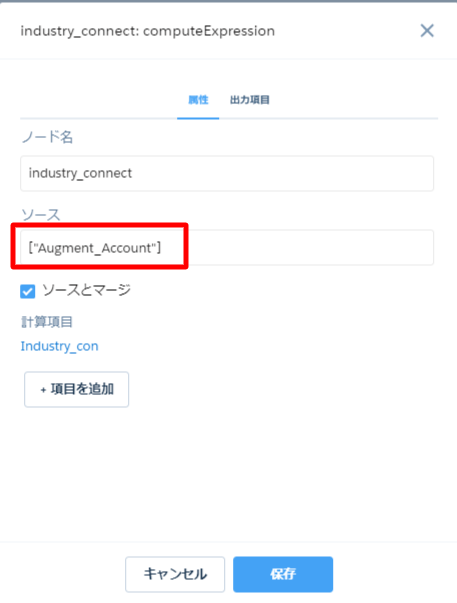
するとデータフローが次のように、左から右へ綺麗に流れるようになります。
最後に「resister」のボックスを見てみます。
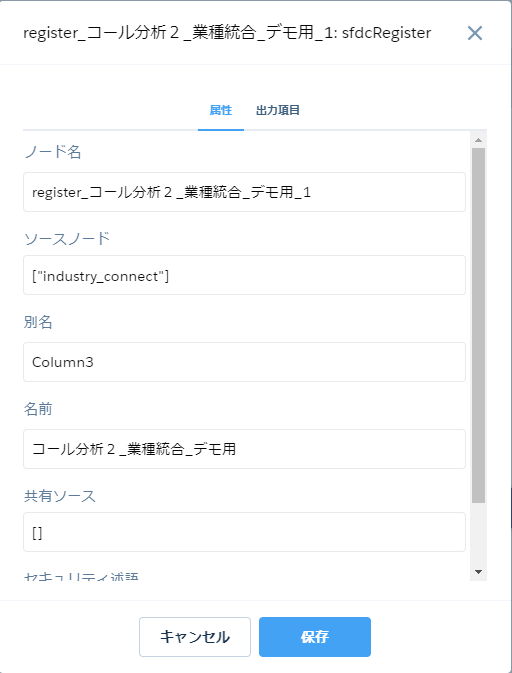
ここで「別名」がデータセットのAPI名になり、「名前」がデータセットの表示名になります。
編集が完了したら画面右上の「データフローの更新」をクリックします。
更新が完了しすると、今度は「データフローの実行」に切り替わりますので、それをクリックすると再びデータセットの更新が行われます。
3.数式を使った項目の追加
上記のフローチャートの中で「computeExpression」というボックスがありました。computeExpressionを使うと数式を使って既存の項目から新たな項目を作成することが出来ます。今回のデータフローでも数式を使って業種をまとめていました。
Augmentの時と同様に上部のアイコンからCompute Expressionを選択します。
ノード名には「Industry_Connent」と入力し、ソースは「Augment_Account」にしています。
「+項目を追加」をクリックして、名前の欄に「API名」表示ラベルに「データの名称」を入力します。
種別については、出力されるデータの型に合わせます。今回はテキストにチェックを入れます。
そしてSAQL式に数式を入力します。数式の結果に応じたデータが、新しい項目として追加されます。
下記が実際に使用した数式です。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
case 'ContactID__c.Field6__c'
when"ゴルフ"then"スポーツ"
else
case 'ContactID__c.Field6__c'
when"スイミング"then"スポーツ"
else
case 'ContactID__c.Field6__c'
when"テニス"then"スポーツ"
else
case 'ContactID__c.Field6__c'
when"フィットネス"then"スポーツ"
else
case 'ContactID__c.Field6__c'
when"フィットネスクラブ"then"スポーツ"
else
case 'ContactID__c.Field6__c'
when"塾"then"学習塾"
else
case 'ContactID__c.Field6__c'
when"整骨院"then"医療・整体"
else
case 'LeadID__c.pi_Class_industry__c'
when"スポーツクラブ"then"スポーツ"
else
case 'LeadID__c.pi_Class_industry__c'
when"医療"then"医療・整体"
else
case 'LeadID__c.pi_Class_industry__c'
when"塾"then"学習塾"
else
case 'LeadID__c.pi_Class_industry__c'
when"教習所"then"教習所"
else "その他"
end
end
end
end
end
end
end
end
end
end
end
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
case関数という数式を使って業種をひとまとめにしました。
この数式で行っている操作を解説しますと、下記の図のようになります。
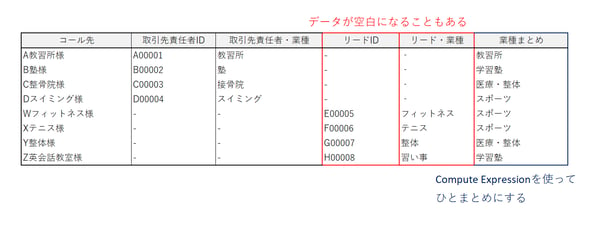
Augmentはデータを横方向にくっつけているので、例えばコールデータに「取引先責任者」「リード」のデータをつなげた場合、図のようにデータに空白の項目が生まれることがあります。
そこで数式を使って
・全てのデータに「業種」が割り振られるようにする
・業種の分類を新しくする(テニス・ゴルフ・スイミングは全て”スポーツ”)
上記二つの操作を行っています。
そのための数式が先ほどの式になります。
このcase関数の基本的な構造は下記の通りになります。
ーーーーーーーーーーーーーーーーーーーーーーー
case ‘〇〇’
when “■■” then ”△△“
else “▲▲”
end
ーーーーーーーーーーーーーーーーーーーーーーー
〇〇について、■■のときは△△にします、そうでないときは▲▲です。
という構文になります。〇〇には判断の元となる項目のAPI名を入力します。■■にはデータまたは条件を、□□には抽出したい結果を記入します。▲▲のところにさらにcase関数を組み込むことで、複数のパターンに応じた結果を得ることが出来ます。
例えば次の文では取引先責任者の業種データのAPIである「ContactID__*c.Field6__*c」について、データが”ゴルフ”になっているときは”スポーツ”に、そうでないときは”その他”に分類する、という数式になります。
ーーーーーーーーーーーーーーーーーーーーーーー
case 'ContactID__c.Field6__c'
when"ゴルフ"then"スポーツ"
else "その他"
end
ーーーーーーーーーーーーーーーーーーーーーーー
これを「ContactID__c.Field6__c」「LeadID__c.pi_Class_industry__c」の各パターンについて入力することで、新しい業種分類を得ることが出来ます。
データ更新のスケジューリング
作成したデータセットはデータフローを実行する度に更新されますが、この更新をスケジューリングすることが出来ます。
データマネージャを開き、画面左から「データフローとマネージャ」を選択し、「データフロー」のタブをクリックします。スケジューリングしたいデータフローをの右端にある▼をクリックします。メニューの中にスケジュールがありますので、ここをクリックします。
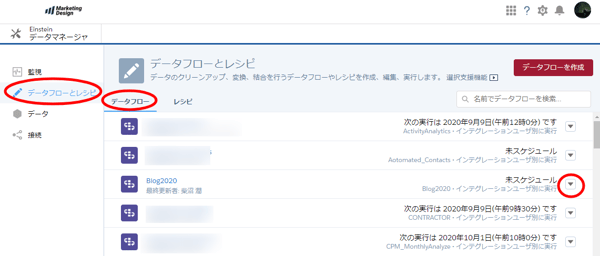
データ更新のスケジュールを入力していきます。
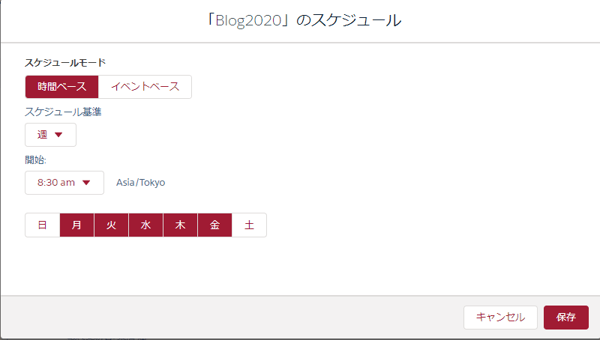
これで指定したタイミングで常にデータが更新されるようになりました。
終わりに
いかがでしたでしょうか?
データフローのつくりを理解するとSalesforceに蓄積されたデータを整理して、より質の高い分析を行うことが出来ます。また、分析データの自動更新はEinstein Analyticsの大きな強みです。
また、データの結合や編集はレシピでも行うことが出来ます。レシピではデータの集計値を取ったり、プレビューを見ながら操作出来ます。今後レシピの活用方法やデータフローとの違いも解説していきますので、お読みいただければと思います。
Einstein Analyticsを使ったデータ分析を行ってみたい方や、導入から基本的な操作の習得までサポートして欲しいという方は是非マーケティングデザインまでお問い合わせください。
ここまで読んでいただきありがとうございました。
柴沼

